Exploring Three Orthogonal Signal Correction (OSC) Algorithms
R
Preprocessing
Chemometrics
Machine Learning
Spectroscopy
Orthogonal signal correction (OSC) is a powerful preprocessing technique frequently used to remove variation in spectral data that is orthogonal to the property of interest. Over the years, several implementations of OSC have emerged, with the most notable being those by Wold et al., Sjöblom et al., and Fearn. This post compares these three methods, exploring their algorithmic approaches and practical implications.
Wold’s method was the first formal OSC algorithm. It operates iteratively to identify orthogonal components unrelated to the dependent variable \(Y\). The method leverages a combination of principal component analysis (PCA) and partial least squares (PLS). Sjöblom’s approach builds on Wold’s by introducing a direct orthogonalization step. The algorithm emphasizes calibration transfer, making it especially useful for standardizing spectral datasets across instruments or conditions. Whereas, Fearn proposed a mathematically elegant version of OSC, simplifying the computation by leveraging matrix operations. The method directly orthogonalizes \(X\) using a singular value decomposition (SVD) of a residual matrix.
Wold’s OSC Algorithm
The Wold algorithm is like a precise sculptor of spectroscopic data. It uses Partial Least Squares (PLS) regression to systematically remove spectral variations that are unrelated to the target variable. The key steps involve:
Initialize \(t\), the first score vector (e.g., using PCA on \(X\)).
Deflate \(t\) using \(Y\): \(t_{\text{new}} = t - Y(Y^\top Y)^{-1}Y^\top t\)
Calculate a loading vector \(p\) from \(t_{\text{new}}\) to model \(X\): \(p = \frac{X^\top t_{\text{new}}}{t_{\text{new}}^\top t_{\text{new}}}\)
Deflate \(X\): \(X_{\text{new}} = X - t_{\text{new}} p^\top\)
Repeat until \(n_{\text{comp}}\).
Show the code
wold_osc <-function(X, Y, ncomp =1, tol =1e-6, max.iter =100) {# Ensure X and Y are matrices X <-as.matrix(X) Y <-as.matrix(Y)# Store the original X matrix X_original <- X# Initialize lists to store components scores <-list() loadings <-list() weights <-list()for (comp inseq_len(ncomp)) {# Step 1: Initial PCA on X to get the first principal component score vector (t) t <-svd(X, nu =1, nv =0)$u *svd(X, nu =1, nv =0)$d[1]# Step 2: Orthogonalize t with respect to Y to obtain t* t_star <- t - Y %*% MASS::ginv(crossprod(Y, Y)) %*%crossprod(Y, t) iter <-0 diff <- tol +1while (diff > tol && iter < max.iter) { iter <- iter +1# Step 3: Compute weights (w) to make Xw as close as possible to t* w <-crossprod(X, t_star) /sum(t_star^2) w <- w /sqrt(sum(w^2)) # Normalize the weights# Step 4: Update t as Xw t_new <- X %*% w# Step 5: Orthogonalize t_new with respect to Y t_star <- t_new - Y %*% MASS::ginv(crossprod(Y, Y)) %*%crossprod(Y, t_new)# Compute convergence criterion diff <-sqrt(sum((t_star - t)^2)) /sqrt(sum(t_star^2))# Update t for the next iteration t <- t_star }if (iter == max.iter) {warning("Iteration limit reached without convergence.") }# Step 6: Compute the loading vector (p) p <-crossprod(X, t_star) /sum(t_star^2)# Step 7: Deflate X X <- X - t_star %*%t(p)# Store results scores[[comp]] <- t_star loadings[[comp]] <- p weights[[comp]] <- w }# Combine components into matrices T_star <-do.call(cbind, scores) P <-do.call(cbind, loadings) W <-do.call(cbind, weights)# Calculate the filtered X matrix X_filtered <- X_original - T_star %*%t(P)# Return results as a listreturn(list(scores = T_star,loadings = P,weights = W,X_filtered = X_filtered ))}
Sjöblom’s OSC Algorithm
Sjöblom’s approach is the pragmatic cousin of the Wold method. It uses similar steps but simplifies certain iterative aspects, focusing on the orthogonal direction more explicitly.
Identify a direction vector \(w\) from \(X\) and \(t\), the orthogonal scores \(w = \frac{X^\top t}{t^\top t}\)
Normalize \(w\): \(w = \frac{w}{\|w\|}\)
Deflate \(t\) from \(Y\) as in Wold’s method.
Remove the orthogonal variation from \(X\): \(X_{\text{new}} = X - t p^\top\)
Iterate for each component.
Show the code
sjoblom_osc <-function(x, y, ncomp, tol, max.iter) { x_original <- x ps <- ws <- ts <-vector("list", ncomp)for (i inseq_len(ncomp)) { pc <- stats::prcomp(x, center =FALSE) t <- pc$x[, 1] .diff <-1 .iter <-0while (.diff > tol && .iter < max.iter) { .iter <- .iter +1 t_new <- t - y %*% MASS::ginv(crossprod(y, y)) %*%crossprod(y, t) w <-crossprod(x, t_new) %*% MASS::ginv(crossprod(t_new, t_new)) w <- w /sqrt(sum(w^2)) t_new <- x %*% w .diff <-sqrt(sum((t_new - t)^2) /sum(t_new^2)) t <- t_new } plsFit <- pls::simpls.fit(x, t, ncomp) w <- plsFit$coefficients[ , , ncomp] t <- x %*% w t <- t - y %*% MASS::ginv(crossprod(y, y)) %*%crossprod(y, t) p <-crossprod(x, t) %*% MASS::ginv(crossprod(t, t)) x <- x -tcrossprod(t, p) ws[[i]] <- w ps[[i]] <- p ts[[i]] <- t } w_ortho <-do.call(cbind, ws) p_ortho <-do.call(cbind, ps) t_ortho <-do.call(cbind, ts) x_osc <- x_original - x_original %*%tcrossprod(w_ortho, p_ortho) R2 <-sum(x_osc^2) /sum(x_original^2) *100 angle <-crossprod(t_ortho, y) norm <- MASS::ginv(sqrt(apply(t_ortho^2, 2, sum) *sum(y^2))) angle <-t(angle) %*%t(norm) angle <-mean(acos(angle) *180/ pi) res <-list("correction"= tibble::as_tibble(x_osc),"weights"= tibble::as_tibble(w_ortho),"scores"= tibble::as_tibble(t_ortho),"loadings"= tibble::as_tibble(p_ortho),"angle"= angle,"R2"= R2 )return(res)}
Fearn’s OSC Algorithm
Fearn’s method stands out by using Singular Value Decomposition (SVD) as its foundation. Its characteristics include:
Compute the residual matrix \(Z\): \(Z = X - Y (Y^\top Y)^{-1} Y^\top X\)
Perform SVD on \(Z\): \(Z = U S V^\top\)
Extract the first \(n_{\text{comp}}\) components from \(V\) and reconstruct the orthogonal scores \(t\) and loadings \(p\): \(t = Z V_{:, i}, \quad p = \frac{X^\top t}{t^\top t}\)
Deflate \(X\): \(X_{\text{new}} = X - t p^\top\)
Show the code
fearn_osc <-function(x, y, ncomp, tol, max.iter) { x_original <- x ps <- ws <- ts <-vector("list", ncomp) m <-diag(row(x)) -crossprod(x, y) %*% MASS::ginv(crossprod(y, x) %*%crossprod(x, y)) %*%crossprod(y, x) z <- x %*% m decomp <-svd(t(z)) u <- decomp$u s <- decomp$d v <- decomp$v g <-diag(s[1:ncomp]) c <- v[, 1:ncomp, drop =FALSE]for (i inseq_len(ncomp)) { w_old <-rep(0, ncol(x)) w_new <-rep(1, ncol(x)) dif <-1 iter <-0while (dif > tol && iter < max.iter) { iter <- iter +1 w_old <- w_new t_new <- c[, i] %*% g[i, i] p_new <-tcrossprod(x, t_new) /tcrossprod(t_new, t_new) w_new <- m %*%tcrossprod(x, p_new) dif <-sqrt(sum((w_new - w_old)^2) /sum(w_new^2)) } ws[[i]] <- w_new ts[[i]] <- c[, i] %*% g[i, i] ps[[i]] <-tcrossprod(x, t[[i]]) /tcrossprod(t[[i]], t[[i]]) } w_ortho <-do.call(cbind, ws) t_ortho <-do.call(cbind, ts) p_ortho <-do.call(cbind, ps) x_osc <- x -tcrossprod(t_ortho, p_ortho) R2 <-sum(x_osc^2) /sum(x_original^2) *100 angle <-crossprod(t_ortho, y) norm <- MASS::ginv(sqrt(apply(t_ortho^2, 2, sum) *sum(y^2))) angle <-t(angle) %*%t(norm) angle <-mean(acos(angle) *180/ pi) res <-list("correction"= tibble::as_tibble(x_osc),"weights"= tibble::as_tibble(w_ortho),"scores"= tibble::as_tibble(t_ortho),"loadings"= tibble::as_tibble(p_ortho),"angle"= angle,"R2"= R2 )return(res)}
Implementation
We begin by implementing these algorithms, creating functions named wold_osc, sjoblom_osc, and fearn_osc. Each function takes five key parameters. The first parameter, x, represents the input data matrix, which typically contains spectral or chemical measurements. The second parameter, y, corresponds to the target variable or response vector. The ncomp parameter specifies the number of orthogonal components to extract, while tol sets the tolerance level for convergence, determining the stopping criterion for iterations. Finally, max.iter establishes the maximum number of iterations allowed during the optimization process. The function definitions for these algorithms follow this structure:
wold_osc <-function(x, y, ncomp, tol, max.iter)sjoblom_osc <-function(x, y, ncomp, tol, max.iter)fearn_osc <-function(x, y, ncomp, tol, max.iter)
To begin, the original data matrix x is stored, and empty lists are initialized to hold the extracted principal components, weights, and scores for each component. This step ensures that the algorithm’s outputs are organized for further processing or analysis:
The algorithm proceeds with a loop to extract the specified number of orthogonal components. For each iteration, Principal Component Analysis (PCA) is performed on the current x matrix without centering, using the stats::prcomp function. The initial score vector t is derived from the first principal component. Variables .iter and .diff are initialized to track the number of iterations and the difference between successive score vectors, which serves as the convergence criterion.
Within the loop, the orthogonalization process begins. Variation correlated with the response variable y is iteratively removed from the score vector t, refining its orthogonality. Weights, representing the relationship between the input matrix x and the score vector, are calculated and normalized to unit length. A new score vector is then computed, and the convergence check compares the difference between successive score vectors (.diff) to the tolerance level (tol). The loop continues until the difference falls below the specified tolerance or the maximum number of iterations is reached.
while (.diff > tol && .iter < max.iter) { .iter <- .iter +1 t_new <- t - y %*% MASS::ginv(crossprod(y, y)) %*%crossprod(y, t) w <-crossprod(x, t_new) %*% MASS::ginv(crossprod(t_new, t_new)) w <- w /sqrt(sum(w^2)) t_new <- x %*% w .diff <-sqrt(sum((t_new - t)^2) /sum(t_new^2)) t <- t_new}
After achieving convergence, a Partial Least Squares (PLS) model is fitted to the data using the extracted scores. The weights and scores are updated, and the loadings are computed. At this stage, y-correlated variation is removed, and the input matrix x is deflated by subtracting the modeled variation. This step prepares the matrix for the next orthogonal component extraction.
The extracted weights, loadings, and scores for each orthogonal component are stored in their respective lists:
ws[[i]] <- wps[[i]] <- pts[[i]] <- t
Once all components are extracted, the results are combined to construct the orthogonal components matrix. The orthogonally corrected matrix x_osc is then computed by removing the contributions of the orthogonal components from the original data matrix:
Finally, to evaluate the algorithm’s performance, two metrics are computed. The percentage of variation removed R2 quantifies how effectively the algorithm deflates the input matrix, while the angle between the orthogonal scores and the target variable y provides insight into the degree of orthogonality achieved. These metrics allow us to assess the quality and effectiveness of the orthogonal signal correction methods.
Exemple
We will use the beer dataset introduced in our previous post. The dataset consists of Near-Infrared Spectroscopy (NIRS) spectra collected from 80 beer samples, x_matrix. The target variable of interest is the Original Gravity (OG), also known as the original extract, y_target. This parameter measures the concentration of dissolved solids in the wort before fermentation begins, providing a crucial indicator of the brewing process.
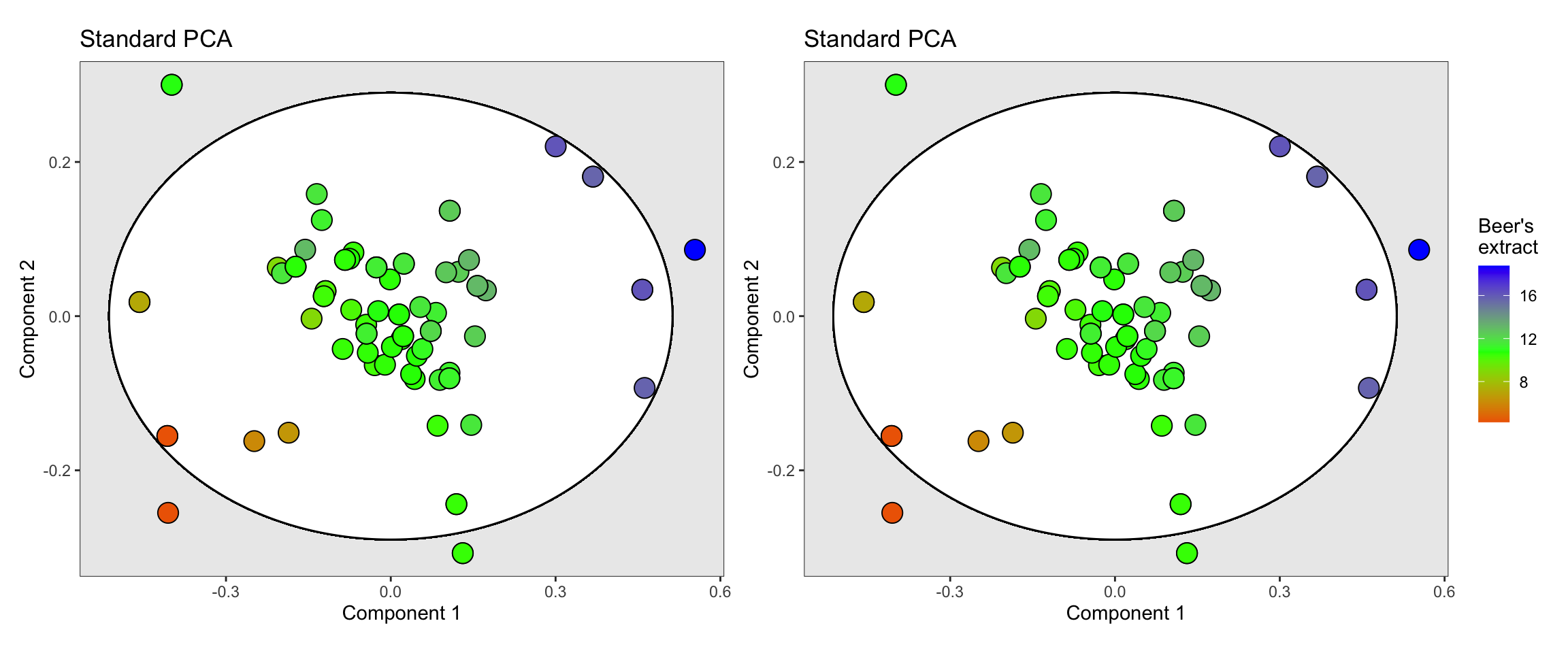
Next, we will perform standard PCA and PLS on the NIRS spectra of the beer dataset to assess how applying orthogonal correction modifies the data structure.
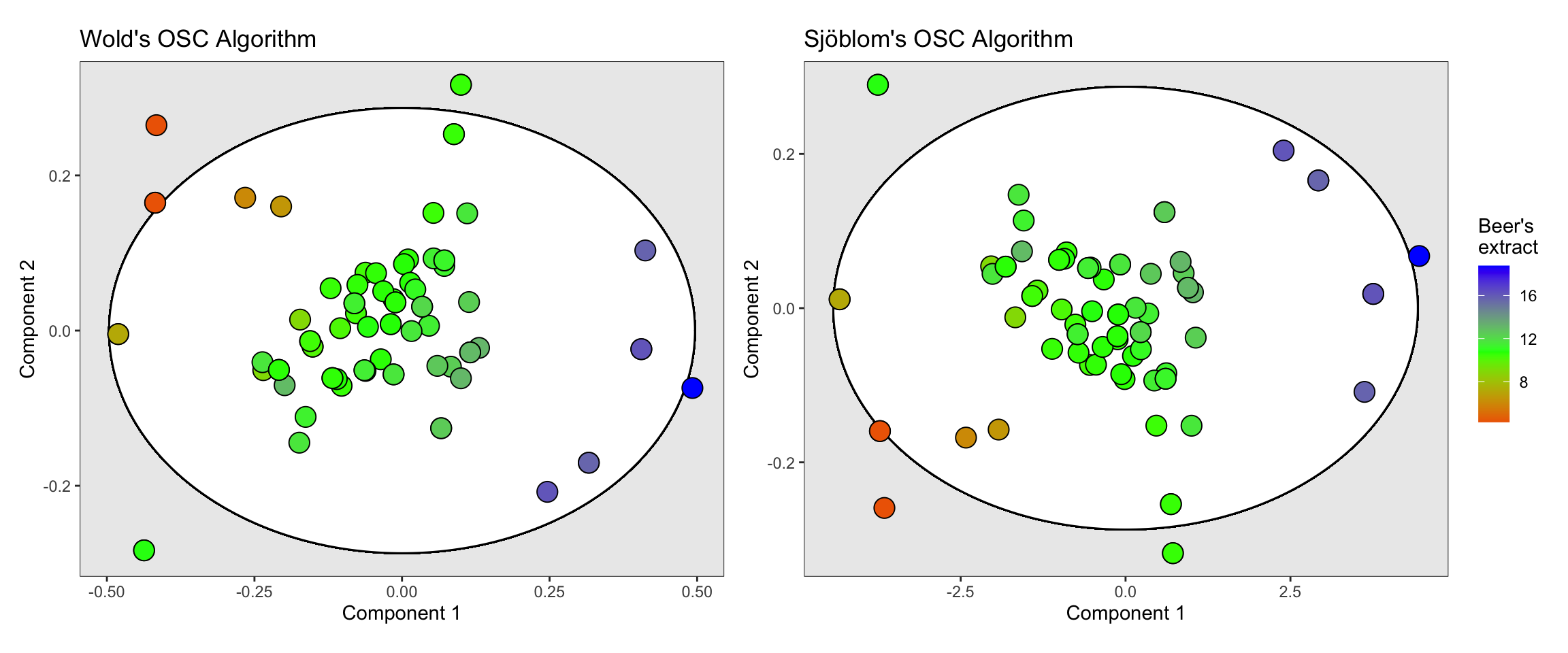
Now, we can apply the OSC algorithms to the dataset and compare their impact. Specifically, we’ll examine how the OSC filtering affects the distribution of samples in the reduced-dimensionality space and whether the variation captured aligns better with the response variable.
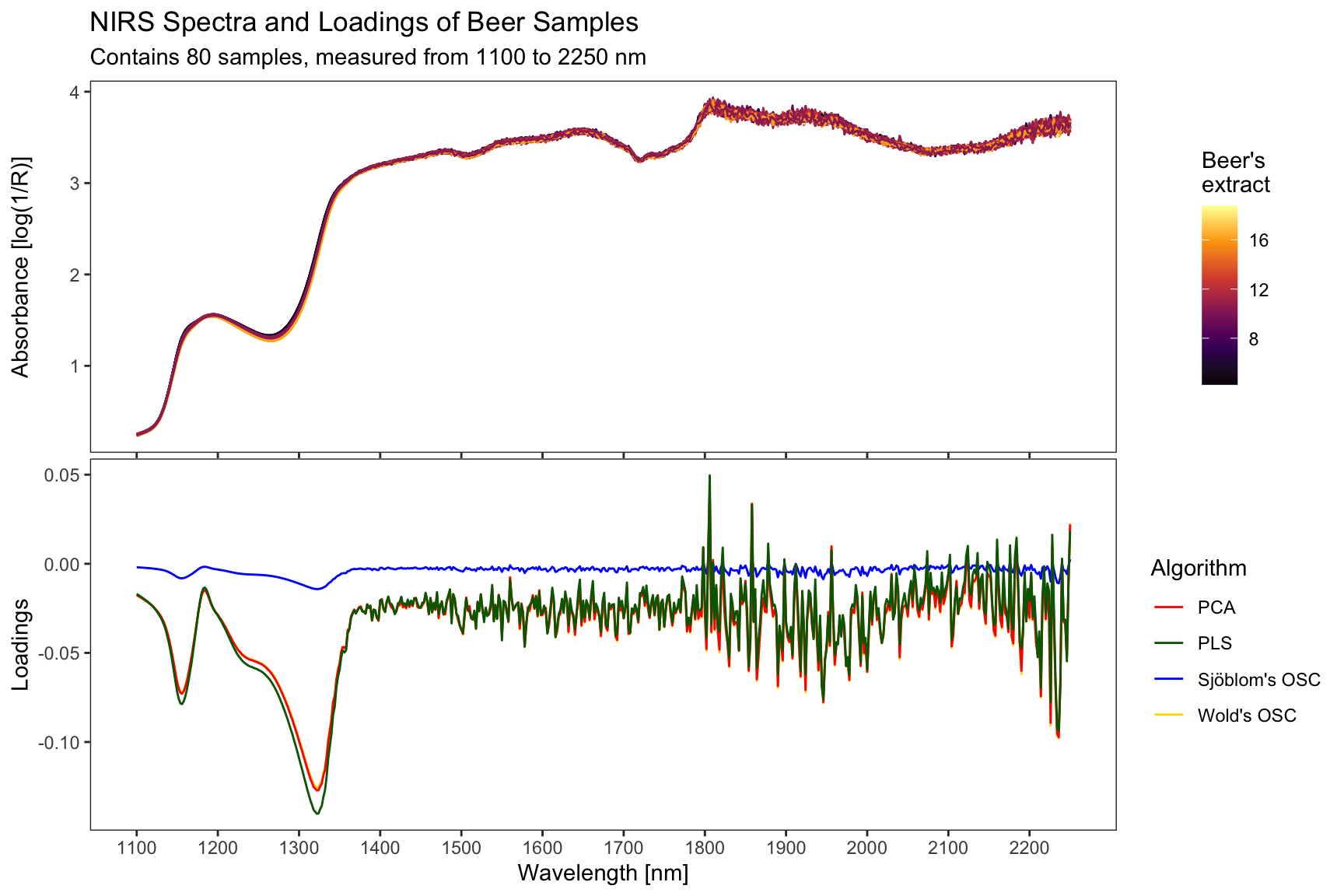
The following plot compares the results of OSC, PCA, and PLS modeling by overlaying their respective loadings on a single graph. By presenting their loadings together, we can clearly observe the differences in how each method captures and prioritizes spectral features and filter noise, highlighting their unique contributions and areas of overlap.
Unlike PCA (in red) and PLS (in dark green), which show substantial variability, particularly in the region above 1350 nm, OSC (in blue) effectively filters the noise, reducing it to near-zero levels. This smoothing demonstrates OSC’s ability to isolate and preserve only the information strongly correlated with the target variable while systematically discarding irrelevant or orthogonal components. However, its aggressive filtering comes at the expense of potentially reducing some useful signal.
The PCA and PLS loadings, on the other hand, display pronounced fluctuations, reflecting their sensitivity to variance within the dataset. PCA, focusing solely on maximizing variance without considering the target variable, captures not only relevant features but also substantial noise. PLS, while more targeted as it incorporates the correlation with the target variable, still exhibits residual noise, especially in the higher wavelengths, indicating its partial retention of irrelevant variance.